YB-TServer Service
The YB-TServer (short for YugabyteDB Tablet Server) service is responsible for the actual IO for end user requests in a YugabyteDB cluster. Recall from the previous section that data for a table is split, or sharded, into tablets. Each tablet is composed of one or more tablet-peers, depending on the replication factor. And each YB-TServer hosts one or more tablet-peers.
Note: We will refer to the “tablet-peers hosted by a YB-TServer” simply as the “tablets hosted by a YB-TServer”.
Below is a pictorial illustration of this in the case of a 4-node YugabyteDB universe, with one table that has 16 tablets and a replication factor of 3.
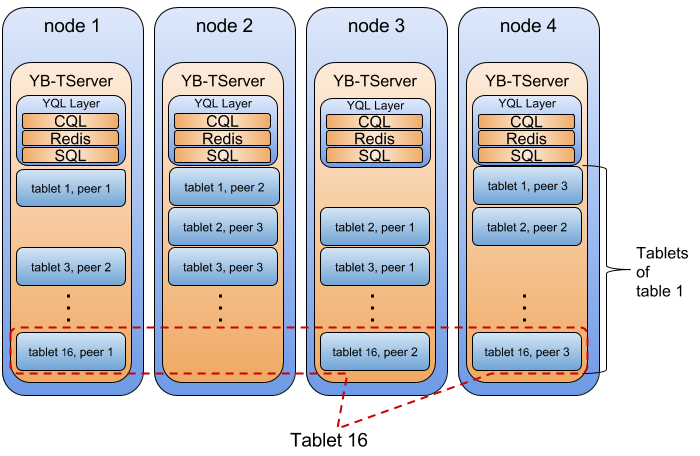
The tablet-peers corresponding to each tablet hosted on different YB-TServers form a Raft group and replicate data between each other. The system shown above comprises of 16 independent Raft groups. The details of this replication are covered in a previous section on replication.
Within each YB-TServer, there is a lot of cross-tablet intelligence built in to maximize resource efficiency. Below are just some of the ways the YB-TServer coordinates operations across tablets hosted by it:
Server-global block cache
The block cache is shared across the different tablets in a given YB-TServer. This leads to highly efficient memory utilization in cases when one tablet is read more often than others. For example, one table may have a read-heavy usage pattern compared to others. The block cache will automatically favor blocks of this table as the block cache is global across all tablet-peers.
Space amplification
YugabyteDB's compactions are size tiered. Size tier compactions have the advantage of lower disk write (IO) amplification when compared to level compactions. There may be a concern that size-tiered compactions have higher space amplification (that it needs 50% space head room). This is not true in YugabyteDB because each table is broken into several tablets and concurrent compactions across tablets are throttled to a certain maximum. Therefore the typical space amplification in YugabyteDB tends to be in the 10-20% range.
Throttled compactions
The compactions are throttled across tablets in a given YB-TServer to prevent compaction storms. This prevents the often dreaded high foreground latencies during a compaction storm.
The default policy makes sure that doing a compaction is worthwhile. The algorithm tries to make sure that the files being compacted are not too disparate in terms of size. For example, it does not make sense to compact a 100GB file with a 1GB file to produce a 101GB file, that would be a lot of unnecessary IO for less gain.
Small and large compaction queues
Compactions are prioritized into large and small compactions with some prioritization to keep the system functional even in extreme IO patterns.
In addition to throttling controls for compactions, YugabyteDB does a variety of internal optimizations to minimize impact of compactions on foreground latencies. One such is a prioritized queue to give priority to small compactions over large compactions to make sure the number of SSTable files for any tablet stays as low as possible.
Manual compactions
YugabyteDB allows compactions to be externally triggered on a table using the compact_table command in the yb-admin utility. This can be useful for cases when new data is not coming into the system for a table anymore, users want to reclaim disk space due to overwrites/deletes that have already happened or due to TTL expiry.
Server-global memstore limit
Tracks and enforces a global size across the memstores for different tablets. This makes sense when there is a skew in the write rate across tablets. For example, the scenario when there are tablets belonging to multiple tables in a single YB-TServer and one of the tables gets a lot more writes than the other tables. The write heavy table is allowed to grow much larger than it could if there was a per-tablet memory limit, allowing good write efficiency.
Auto-sizing of block cache/memstore
The block cache and memstores represent some of the larger memory-consuming components. Since these are global across all the tablet-peers, this makes memory management and sizing of these components across a variety of workloads very easy. In fact, based on the RAM available on the system, the YB-TServer automatically gives a certain percentage of the total available memory to the block cache, and another percentage to memstores.
Striping tablet load uniformly across data disks
On multi-SSD machines, the data (SSTable) and WAL (Raft write-ahead log) for various tablets of tables are evenly distributed across the attached disks on a per-table basis. This ensures that each disk handles an even amount of load for each table.